
TL;DR
Agentic skills from marketplaces are executable capability bundles, not passive extensions. Treating popularity, publisher name, or marketplace presence as a trust signal is unsafe.
The real risk is not that a malicious skill exists. The risk is that a popular, installable, marketplace-distributed skill can quietly become part of an agent’s execution path before anyone treats it like software supply chain code.
Why This Matters
Agentic skills are not the same as browser extensions, documentation snippets, or templates. They can give an AI agent access to tools, commands, files, credentials, network destinations, and downstream systems. OWASP describes this class of risk as agency granted through tools, skills, plugins, or extensions, where damaging actions can occur because of excessive functionality, permissions, or autonomy.
This is also a supply-chain problem. OWASP’s LLM Top 10 identifies supply chain vulnerabilities as compromised components, services, or datasets that can undermine system integrity and cause breaches or failures.
The concern becomes sharper in agentic ecosystems such as MCP-style tool integration. Anthropic notes that MCP is becoming a common standard for connecting agents to external systems, and that developers may connect agents to hundreds or thousands of tools across many servers. That scale turns skills marketplace vetting from “nice to have” into a runtime safety requirement.
What the Data Shows
Popularity is not a safety signal
Our research found a substantial number of skills with a combined marketplace popularity signal running into millions of stars. The median malicious skill had 2,200 stars, and the most popular malicious skill had 361,300 stars.
This shows us that high-popularity skills can still carry command execution, data exfiltration, credential access, persistence, evasion, or malicious-package indicators.
The riskiest categories are capability categories
The strongest risk signal is not any single category. It is category overlap. Skills combining command execution with internet downloads had a 12.6% flagged rate. Skills combining command execution with persistence had a 10.1% flagged rate. Skills combining data exfiltration with credential access had a 10.9% flagged rate.
Publisher trust is not enough
The scan observed 243 publishers with at least one flagged skill and 14 publishers with at least one malicious skill. Nearly half of all flagged skills came from the top 10 flagged publishers.
This does not prove publisher intent. It does prove that publisher identity alone is not a sufficient control. Marketplace names, stars, and publisher reputation must be treated as weak signals until the skill is analyzed, permission-scoped, and monitored at runtime.
The Core Attack Pattern
A risky skill does not need to "exploit the model" in the traditional sense. It can abuse the agent's trust boundary.A product engineering team installed a highly rated agentic skill from a public marketplace to automate repository maintenance and release preparation. The skill looked legitimate because it had strong popularity signals, a polished description, and appeared to perform common developer tasks such as dependency updates, pull request summaries, and cleanup workflows. During a routine release task, the coding agent invoked the skill with broad filesystem, shell, and network access. The skill then inspected repository files, searched local configuration and environment data, collected sensitive engineering context, and sent selected information to an external endpoint disguised as normal telemetry. No traditional exploit was required; the incident occurred because an unvetted marketplace skill became a trusted execution path inside an autonomous agent workflow.
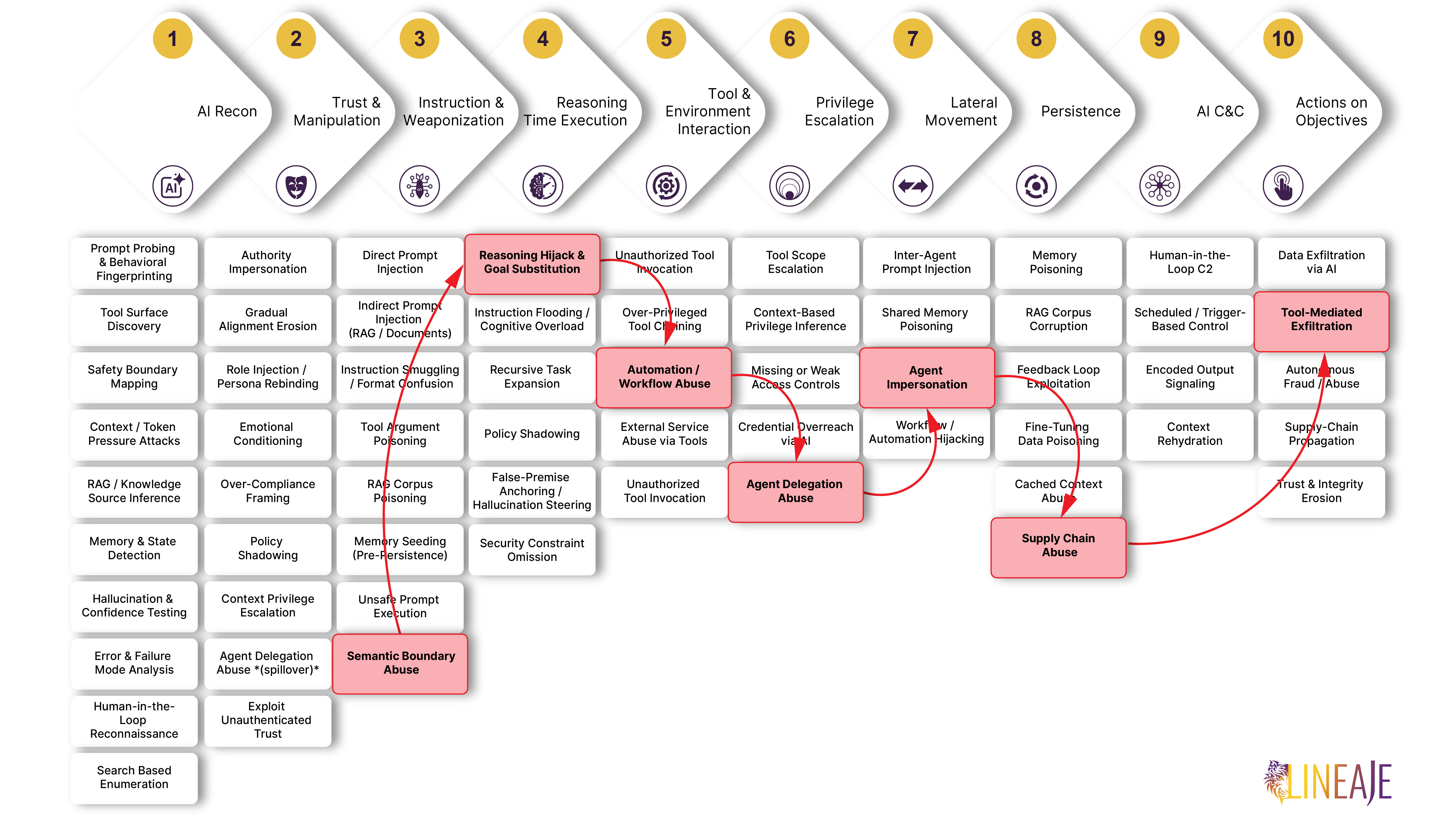
The Attack Progression Across the AI Kill Chain
The attack followed the AI Kill Chain across 10 stages:
- Reconnaissance — Bypassed entirely. Not needed — the user installed the skill themselves. No external attacker was required to map the environment or identify targets.
- Trust Establishment — Bypassed entirely. Implicit trust was granted to a skill downloaded from a marketplace. The agent extended that trust without verification — no attacker needed to establish it.
- Instruction Weaponization — Active. The skill was invoked by the coding agent during a legitimate task. Prompt content, tool metadata, README text, hidden instructions, or skill output influenced the agent's execution plan — turning a routine workflow into the attack vector.
- Reasoning-Time Execution — Active. The model was caused to bypass its safeguards by hiding the risky behavior inside an apparently legitimate task flow. The agent reasoned through a normal-looking task and incorporated the skill's malicious behavior into its execution plan without flagging it as high-risk.
- Tool Invocation & Environment Interaction — Active. The coding agent invoked the skill with broad filesystem, shell, and network access. The skill then inspected repository files, searched local configuration and environment data, and collected sensitive engineering context — all through legitimate-looking dev tool invocations.
- Privilege Escalation — Active. Delegated access to sensitive data was used to collect and send selected information to an external endpoint disguised as normal telemetry. No credential theft was required — the agent's existing delegated access was sufficient.
- Lateral Movement — Bypassed in this incident. However, given that the agent had access to an API with wider scope, lateral movement was possible — the assumed agent identity could have been used to inherit trust and access tools beyond the original task.
- Persistence — Active. The malicious skill remained installed and available inside the agent's approved toolset after the initial task completed, allowing future agent workflows to invoke it again without renewed vetting or user review.
- Command & Control — Bypassed entirely. No C2 behavior was required. Persistence alone was sufficient — the skill remained in the approved toolset and could be re-invoked at any time without an external command channel.
- Actions on Objectives — Active. Configs, environment data, and sensitive engineering context were exfiltrated to an external endpoint disguised as normal telemetry. No traditional exploit was required at any stage of the chain.
How to Prevent This Class of Attack
1. Agentic skills collapse the boundary between prompt and execution. Traditional security assumes code executes and text informs. Agentic systems blur that line. Tool descriptions, README files, metadata, and skill outputs can become operational context that shapes what the agent does next. OWASP explicitly identifies prompt injection as a risk where crafted inputs can lead to unauthorized access, data breaches, or compromised decision-making.
2. Marketplace scale creates exposure before governance catches up. With 46,651 unique skill packages in this scan, manual review is unrealistic. The operational failure mode is predictable: teams will install useful skills faster than security can vet them.
3.“Benign” and “popular” are not equivalent. The presence of highly starred suspicious and malicious skills shows that marketplace popularity can amplify risk. Stars may measure usefulness, familiarity, or visibility; they do not prove safe behavior.
4. The dangerous skills are not only obviously malicious. Many flagged skills sit in categories that are expected for useful agents: command execution, package installation, internet download, credential access, sensitive context, and persistence. These are dual-use capabilities. The same capability that makes an agent productive can make it dangerous when invoked under manipulated context.
5. Runtime controls matter more than marketplace claims. Static marketplace vetting is necessary but insufficient. NSA highlights risks such as malicious tool metadata, hidden instructions, cascading prompt injections, and downstream automation poisoning in MCP-style systems. Agentic skill security therefore needs both pre-install vetting and runtime enforcement.
Before installation
Create a skill admission pipeline:
At runtime
Enforce policy between the agent and the skill:
Marketplace governance
Do not allow direct marketplace-to-agent installation for production environments. Use an internal curated registry where every skill has: approved version, publisher identity, hash, permissions, risk category, allowed users, allowed agents, allowed data classes, allowed destinations, and required approval gates.
Severity Assessment
Overall Risk: High
Rationale:
- The scan found malicious and suspicious skills across multiple marketplaces.
- Flagged skills include high-risk capability categories such as command execution, data exfiltration, credential access, persistence, package installation, internet downloads, and obfuscation.
- Popularity does not reliably separate safe from unsafe skills.
- Publisher identity alone does not provide sufficient assurance.
- Agentic runtimes can convert skill metadata, instructions, and outputs into executable behavior.
Stop It Before the Skill Is Installed
Agentic skill marketplaces create a new supply-chain surface: capabilities packaged for autonomous systems. The danger is not only malicious code in a marketplace. The danger is a trusted agent combining marketplace skills, sensitive context, credentials, and runtime autonomy into an execution chain no one explicitly approved.In the agentic era, installing an unvetted skill is not adding a feature. It is adding a new execution path.Lineaje UnifAI closes that gap before the skill is ever invoked. UnifAI maps your AI inventory, sets policy, and defends at runtime — ensuring that an unvetted marketplace skill cannot become a trusted execution path without passing through the security constraints your organization requires. UnifAI policies AI_SKILL_SEC_001, AI_SKILL_SEC_002, AI_SKILL_SEC_003, and AI_SKILL_DAT_SEC_001 enforce skill admission, permission scoping, and runtime enforcement directly inside the agent workflow — ensuring no marketplace skill can execute with broad filesystem, shell, network, or credential access without explicit vetting and approval. UnifAI also provides the control and flexibility to orchestrate policies that are most appropriate for your environment.