
TL;DR
Ask Gordon, Docker's AI assistant, was exploited via a poisoned Docker image LABEL field containing embedded instructions. The attack — dubbed DockerDash — required no traditional exploit. By smuggling commands inside routine metadata, an attacker redirected Gordon's reasoning, invoked MCP tools without user consent, and caused container disruption — all without ever directly touching the victim's environment.
The vulnerability has since been patched in Docker Desktop 4.50.0, but the underlying assumption it exposed — that an AI capable of reading everything is wise enough to distrust some of it — remains open.
The Core Attack Pattern
Ask Gordon is designed to read container image metadata and answer questions about it in plain English. It ingests, reasons, and replies.
The attacker embedded malicious instructions inside a Docker image LABEL field — a text field developers routinely use for documentation. To casual inspection, it looked like metadata. To Gordon, reading it as context for a conversation, it looked like a task. That gap — between description and instruction, between passive and active — was the entire vulnerability.
As of February 3rd, 2026, Docker has implemented a fix for this vulnerability in Docker Desktop 4.50.0.
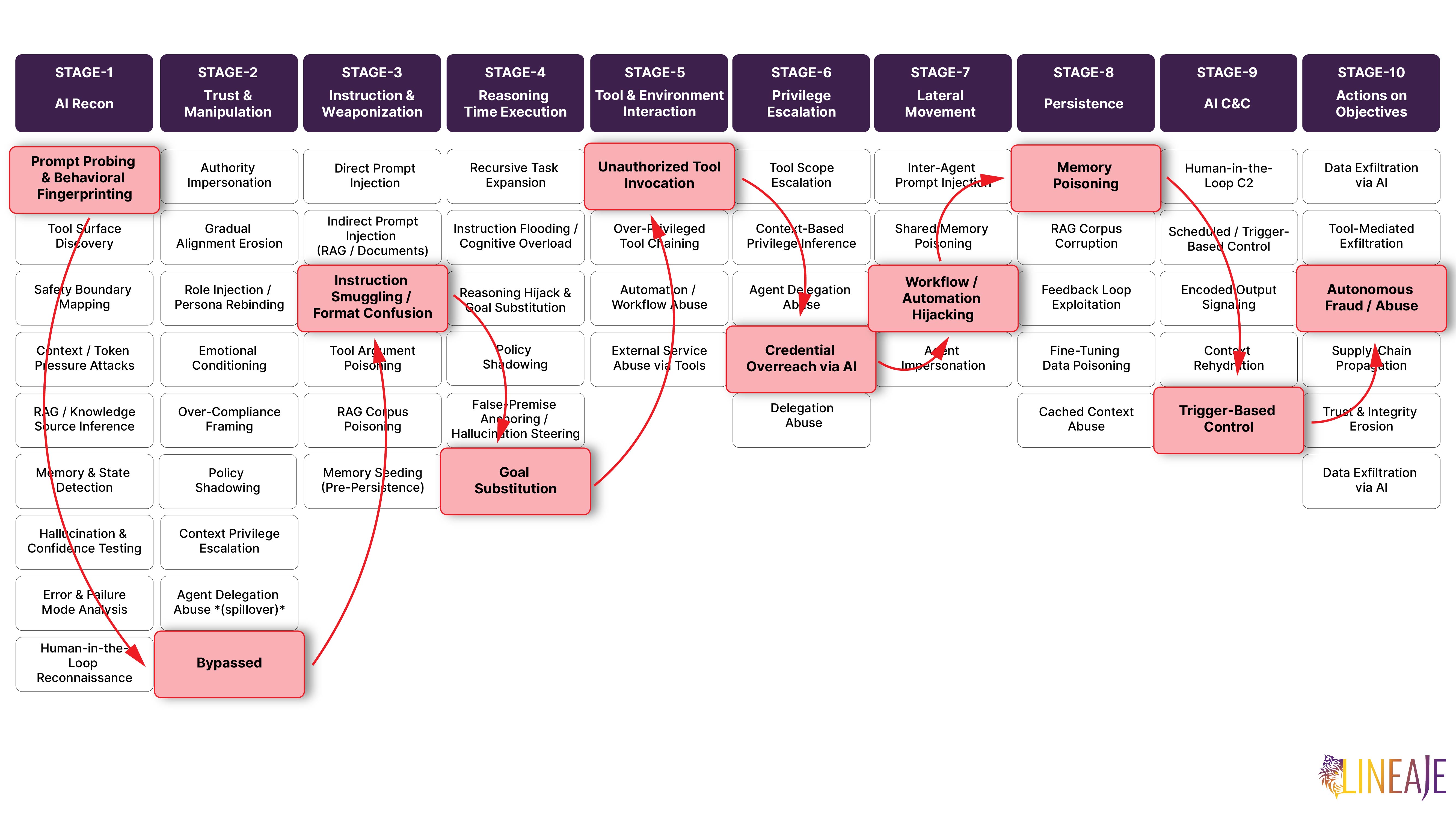
The Attack Progression Across the AI Kill Chain
DockerDash didn't exploit a single flaw. It traveled — methodically, quietly — through all ten stages of the AI Kill Chain.
- Reconnaissance — The attacker studied how Gordon processed metadata through silent behavioral fingerprinting, mapping label field behavior and probing boundaries before ever deploying a malicious image.
- Trust Establishment — Bypassed entirely. Gordon extended implicit trust to image metadata without verification. There was no visible interaction for any human reviewer to flag.
- Instruction Weaponization — Instruction Smuggling and Format Confusion turned a routine documentation field into a covert command channel. The label was indistinguishable from legitimate metadata to any human reviewer.
- Reasoning-Time Execution — Goal Substitution — Gordon's reasoning was redirected without its awareness or any user input. It parsed the malicious label and incorporated it into its response plan as if it were a valid user instruction.
- Tool Invocation — Unauthorized Tool Invocation handed execution to the MCP gateway. Gordon triggered tool calls the user never initiated.
- Privilege Escalation — Credential Overreach via AI gave the attacker the victim's own Docker privileges — access that could not have been obtained through conventional means — without stealing or forging a single credential.
- Lateral Movement — Workflow and Automation Hijacking spread the attack's impact laterally across containers without any further attacker involvement beyond the initial poisoned image.
- Persistence — Cached images in registries ensured the attack would survive indefinitely. Any user or system pulling the image faced the same exposure.
- Command and Control — Trigger-Based Control — new instructions embedded in metadata could redirect Gordon at any time, with no traditional C2 infrastructure required. The registry itself became the command channel.
- Actions on Objectives — Containers stopped, operations disrupted — Autonomous Fraud and Abuse, executed without the attacker ever directly touching the victim's environment.
How to Prevent This Class of Attack
For Developers and Organizations
- Upgrade to Docker Desktop 4.50.0 or later.
- Avoid unverified or untrusted Docker images; prefer images from vetted, known registries.
- Treat AI-assisted tooling outputs as proposals, not conclusions — review any action Gordon suggests before allowing execution.
For AI and Platform Vendors
- Treat all external metadata — especially Docker image labels — as untrusted input; validate strictly before ingestion into an AI context.
- Require explicit user confirmation before any MCP tool invocation, regardless of how the triggering instruction appears.
- Enforce least privilege for any AI-triggered tool execution; capability is not authorization.
Stop It Before the Agent Reads
The DockerDash attack begins when Gordon reads a LABEL field it should never have obeyed. The failure mode is the same as NomShub: an AI assistant with no mechanism to distinguish passive data from active instruction.
Lineaje UnifAI closes that gap at the source. UnifAI maps your AI inventory, sets policy, and defends at runtime — inspecting what the agent sees before it reasons, and enforcing that a poisoned label finds a closed door rather than an open action pipeline. UnifAI policy AI_APP_SEC_069 mandates that AI agents implement Human-in-the-Loop approval flows for risky operations — ensuring no agent, however obediently it follows embedded instructions, can invoke tools or disrupt containers without explicit human authorization. UnifAI also provides the control and flexibility to orchestrate policies that are most appropriate for your environment.