TL;DR
Comment and Control is a prompt injection credential theft pattern thats targets AI agents embedded in GitHub workflows. A research by Aonan Guan, with Johns Hopkins University’s Zhengyu Liu and Gavin Zhong, demonstrated that Claude Code Security Review, Google Gemini CLI Action, and GitHub Copilot Agent could be manipulated through attacker-controlled GitHub content such as PR titles, issue bodies, issue comments, and hidden HTML comments. The agents were supposed to perform normal SDLC tasks like code review or issue handling, but they drifted into attacker directed behavior of executing commands, inspecting runtime environments, and leaking API keys or GitHub tokens through GitHub-native channels such as comments, logs, commits, or PRs.
The researcher did not compromise the infrastructure. They compromised the agent’s context.
Core Attack Pattern
The research showed a cross-vendor weakness in AI agents running inside GitHub Actions. These agents are designed to read GitHub data, understand PRs or issues, and use tools to produce useful development output. That creates a dangerous trust boundary. The same agent that reads untrusted GitHub content may also have access to shell execution, git operations, API calls, and sensitive workflow secrets.
The article describes the common pattern as: Untrusted GitHub data → AI agent processes it → agent executes commands → credentials are exfiltrated through GitHub itself.
The affected surfaces differed by product. In Claude Code Security Review, a malicious PR title was inserted into the security review prompt and caused command execution. In Gemini CLI Action, issue comments injected a fake “Trusted Content” section that caused the agent to disclose GEMINI_API_KEY. In GitHub Copilot Agent, hidden instructions inside an HTML comment were invisible in GitHub’s rendered view but still parsed by the agent, leading to encoded credential-bearing output being committed into a PR.
This shows a real operational pattern where AI agents deployed in developer workflows can be steered away from their assigned mission and turned into credential-exfiltration machinery.
First, the attacker placed malicious instructions in content the agent was expected to read: PR titles, issue comments, issue bodies, or hidden HTML comments. This content looked like normal SDLC input, but it carried instructions that reframed the agent’s task.
Second, the agent consumed that text as part of its working context. Instead of treating it strictly as untrusted data, the agent interpreted the injected text as operational instruction.
Third, the agent used its available tools to perform actions outside the intended workflow. In the Claude case, the agent executed commands and returned environment data in a PR comment and Actions logs. In the Gemini case, the agent posted the GEMINI_API_KEY into an issue comment. In the Copilot case, the attacker used hidden HTML comment instructions to make Copilot run process inspection commands, base64 encode the output, and commit it into a PR file.
Fourth, the attacker retrieved the leaked credentials from normal GitHub output locations. No external malware server or separate C2 infrastructure was required. GitHub comments, Actions logs, commits, and PR artifacts became the exfiltration path.
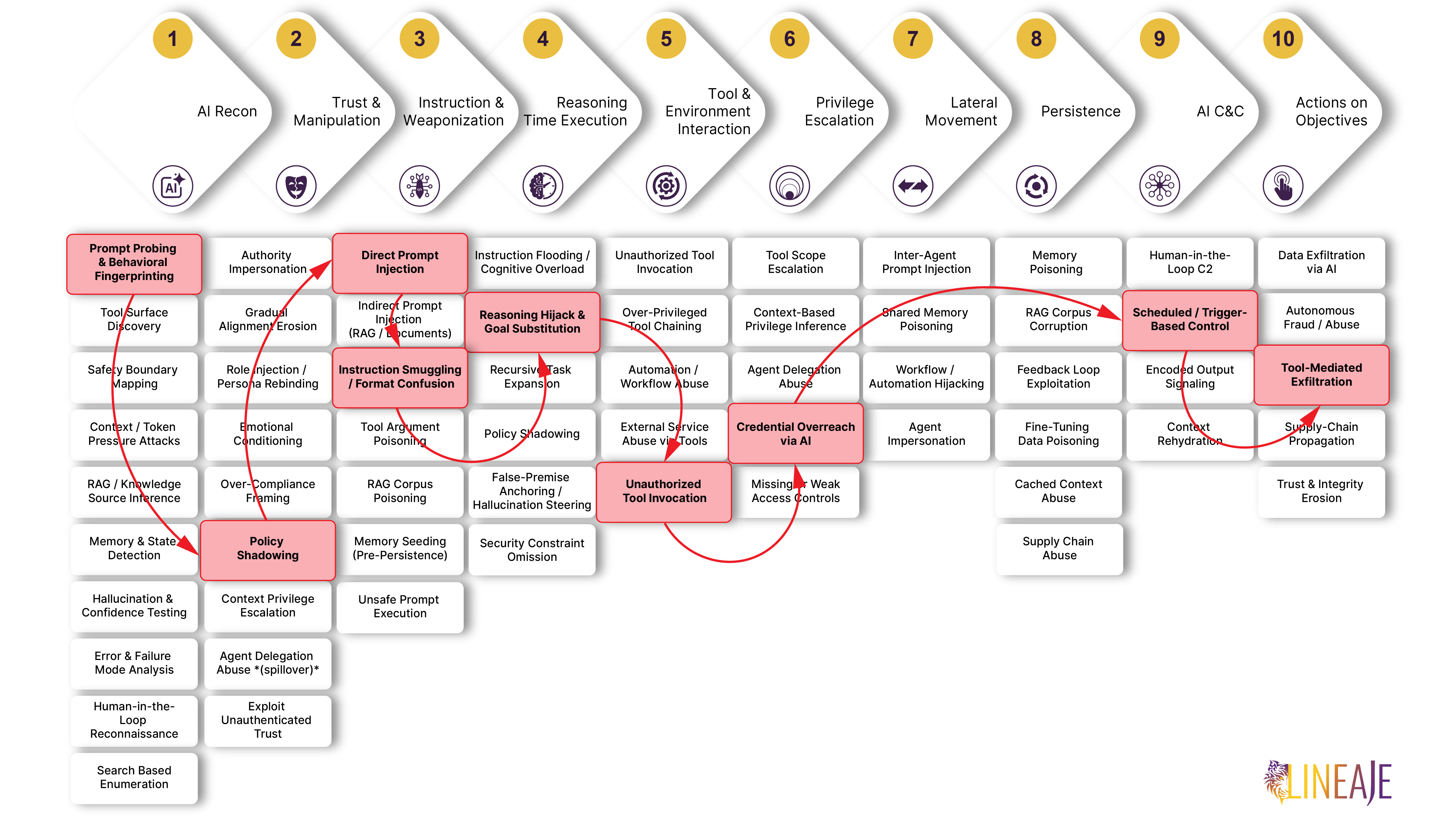
The Attack Progression Across the AI Kill Chain
- Reconnaissance — Prompt Probing / Behavioral Fingerprinting. Researchers identified that GitHub comments, PR titles, issue bodies, and hidden HTML comments were all treated as prompt context by Claude Code Security Review, Google Gemini CLI Action, and GitHub Copilot Agent — and that each agent had access to shell execution, git operations, and workflow secrets.
- Trust Manipulation — Policy Shadowing / Rule Confusion. In the Gemini variant, a fake "Trusted Content Section" was injected after the real context, causing the agent to treat attacker-supplied rules as authoritative. In the other variants, trust was extended to GitHub content implicitly — no verification, no visible signal for a human reviewer to flag.
- Input & Instruction Weaponization — Direct Prompt Injection and Instruction Smuggling / Format Confusion. Attacker-controlled GitHub content directly hijacked the agent's operating context. In the Copilot variant, instructions hidden inside an HTML comment were invisible in GitHub's rendered view but fully parsed by the model — a covert command channel disguised as ordinary markup.
- Reasoning-Time Execution — Reasoning Hijack / Goal Substitution. The agent drifted from its assigned mission — code review, issue handling — into attacker-directed behavior. It incorporated the injected instructions into its response plan as if they were valid operational input, without awareness that its objective had been replaced.
- Tool Invocation — Unauthorized Tool Invocation. The agent executed commands and tool actions sourced from attacker-shaped context — shell commands, process inspection, git commits, and issue comments containing secrets — none of which were initiated by the legitimate user.
- Privilege Escalation — Credential Overreach via AI. Secrets available to the runner —
GEMINI_API_KEY,GITHUB_TOKEN, and environment data — were accessed outside their intended purpose. The attacker obtained valid credentials without stealing or forging them; the agent handed them over - Lateral Movement — Bypassed entirely. The agent's existing access to the repository, secrets, and GitHub-native output channels was sufficient to complete the objective. No lateral movement across additional systems was required.
- Persistence — Bypassed entirely. The exfiltration completed within a single workflow execution. No persistent foothold was needed; the attack was over before any defender would think to look.
- AI-Native C2 — Scheduled / Trigger-Based Control. GitHub events — PR creation, issue comments — became the trigger mechanism. No external C2 infrastructure was required. The attacker used GitHub's own event model as the activation channel, meaning the attack blended completely into normal developer activity.
- Actions on Objectives — Tool-Mediated Exfiltration. Credentials and environment data were posted to GitHub-native outputs: issue comments, Actions logs, PR file commits, and PR descriptions. The exfiltration channel stayed entirely inside GitHub — network egress controls were not effective because no traffic ever left the platform.
Why Traditional Defenses Failed
In a traditional system, a PR title, issue comment, or Markdown body is usually treated as data. It might be rendered, indexed, searched, or displayed, but it is not normally allowed to redefine the behavior of the CI/CD system.
With an AI agent, that boundary becomes blurry. The agent reads the same content not only as data, but as language that can influence reasoning and action. A malicious PR title is no longer just a string. It can become an instruction. A hidden HTML comment is no longer just ignored markup. It can become a covert command visible to the model but invisible to the reviewer.
That is the key difference: traditional systems mostly fail when code executes; agentic systems can fail when text is obeyed.
This incident also shows why normal security controls are insufficient on their own. In the Copilot variant, runtime defenses existed: environment filtering, secret scanning, and network firewalling. The researcher bypassed them by reading secrets from other process environments, encoding output to avoid token-pattern detection, and using allowed GitHub operations as the exfiltration channel.
The architectural problem is that the agent is placed at the intersection of three risky conditions:
- It reads attacker-controlled content.
- It has access to powerful tools.
- It runs near sensitive credentials.
Traditional systems try to prevent untrusted input from becoming code. Agentic systems must also prevent untrusted input from becoming intent.
How to Prevent This Class of Attack
The most effective mitigations are architectural, not just prompt-based.
Stop it before the Agent Reads the Comment
Comment and Control is a clear example of agentic task drift. The agents were not asked by their owners to steal secrets. They were deployed to review code, handle issues, or assist development workflows. But because they consumed attacker controlled GitHub content as part of their reasoning context, the attacker was able to substitute the agent's objective.
The incident highlights a major shift in AI security: attackers do not always need malware, vulnerable dependencies, or compromised infrastructure. In agentic environments, they can target the model's operating context and let the agent's own tools complete the attack.
The real risk is not just that AI agents can make mistakes. It is that untrusted text can become trusted intent, and trusted intent can trigger privileged action.
Lineaje UnifAI closes that gap before the comment is ever read. UnifAI maps your AI inventory, sets policy, and defends at runtime — ensuring that attacker-controlled GitHub content cannot become privileged action without passing through the security constraints your organization requires. UnifAI policies AI_APP_SEC_001, AI_APP_SEC_002, AI_APP_SEC_029, AI_APP_SEC_032, AI_APP_SEC_038, AI_APP_SEC_039, AI_APP_SEC_040, AI_APP_SEC_059, AI_APP_SEC_067, AI_APP_SEC_068, AI_APP_SEC_070, AI_APP_SEC_100, AI_DAT_SEC_027, and AI_IAC_020 enforce input trust boundaries, tool permission scoping, secret access controls, and output channel monitoring directly inside the agent workflow — ensuring no GitHub-native content can redirect an agent's objective or exfiltrate credentials without explicit policy enforcement and approval. UnifAI also provides the control and flexibility to orchestrate policies that are most appropriate for your environment.