

TL;DR
AI infrastructure is being deployed faster than it is being secured. A large-scale scan of internet facing AI services found exposed chatbots, unauthenticated LLM APIs, open agent-management platforms, visible workflows, exposed prompts, exposed conversation histories, and tool connected AI systems reachable from the public internet.
The core threat is not only data leakage. The deeper risk is that exposed AI systems increasingly sit between users, models, tools, credentials, workflows, and business systems. When these systems are unauthenticated or misconfigured, attackers may not need to exploit the model. They can simply access the AI control surface directly.
This is a classic exposure problem amplified by AI-native blast radius: one open chatbot may leak conversations; one open agent platform may expose workflows; one open tool connected agent may become a path to data exfiltration, workflow modification, code execution, or unauthorized use of paid frontier models.
The Core Exposure Pattern
Researchers scanned public internet infrastructure associated with AI services and found widespread exposure across self-hosted AI applications, LLM front ends, agent management platforms, and model APIs.
The scan identified a large number of AI services exposed to the internet, many deployed with weak defaults or no authentication. The exposed services included chatbot interfaces, OpenUI-based deployments, Flowise and n8n agent-management platforms, and Ollama APIs.
Several categories of exposure were observed:
- Chatbots exposing user conversation history.
- Chatbot services allowing public use of hosted models.
- AI applications disclosing plaintext API keys.
- Agent-management platforms exposing prompts, workflows, business logic, and outward integrations.
- Credential lists visible in management interfaces, even where stored secret values were not directly disclosed.
- Tool connected agents with access to web parsing, file writes, code interpretation, and other high-risk functions.
- Unauthenticated Ollama APIs responding to simple prompts.
- Exposed servers wrapping paid frontier models from major model providers.
- Lab reviewed AI applications showing insecure defaults, hardcoded credentials, static credentials, root execution, and weak deployment patterns.
This was not described as a single intrusion. It was a large scale exposure finding that demonstrates how AI infrastructure is becoming publicly reachable without the basic controls expected for production systems.
The reported activity was conducted by researchers, not by a confirmed attacker campaign. However, the attacker path is straightforward. An attacker can discover exposed AI services, access unauthenticated interfaces, inspect prompts and workflows, identify connected tools, abuse model APIs, modify agent behavior where management access is open, and attempt to pivot through integrations.
The most important point is that many of these systems do not require prompt injection to begin the attack. The attacker may already have direct access to the AI application, model endpoint, or agent-management plane.
Once inside the exposed AI interface, the attacker can use AI native techniques:
- Query the exposed model to understand purpose and connected capabilities.
- Inspect chat history for sensitive data, internal context, credentials, or business information.
- Review prompts and workflows to identify business logic.
- Abuse connected tools to access third party systems.
- Modify agent workflows to redirect data or poison responses.
- Use someone else's infrastructure to run models, including paid frontier models.
- Attempt jailbreaks or misuse prompts against exposed models without attribution to the attacker's own account.
- Use code interpretation, file write functions, or unsafe local tools to attempt server side execution.
The dangerous shift is that exposed AI infrastructure often combines three layers that were traditionally separate: user facing interface, reasoning layer, and operational tooling. When all three are reachable without authentication, the exposed service becomes both an information source and an action surface.
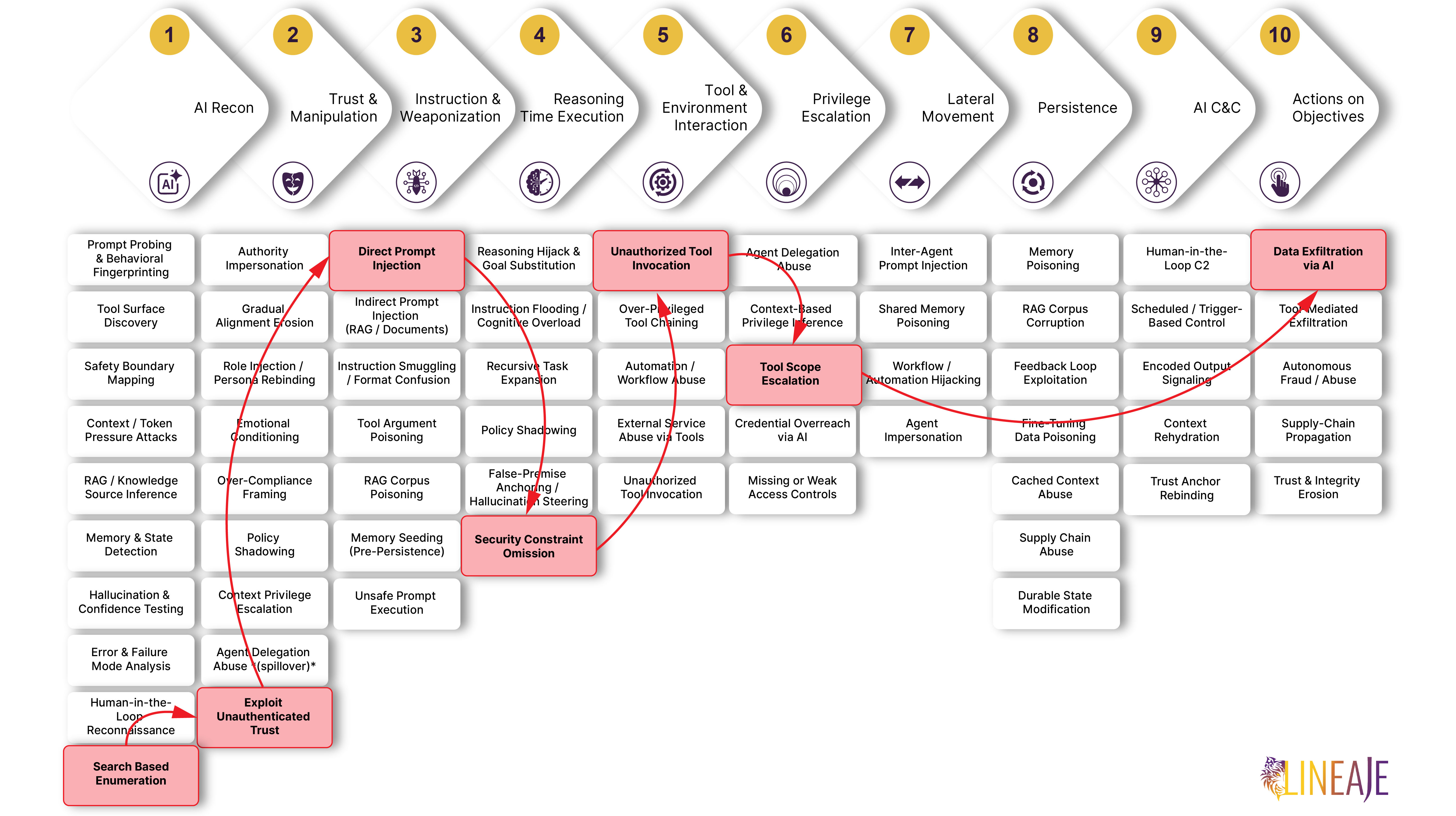
The Incident Progression Across the AI Kill Chain
- Reconnaissance — Asset Discovery / Search-Based Enumeration. Researchers used certificate transparency logs to identify internet facing and exposed AI related hosts and services.
- Trust Manipulation — Bypassed entirely. The primary issue was not social trust manipulation; the services were directly exposed. No attacker had to deceive a user or work a trust relationship — the trust that failed was structural, the implicit assumption that these endpoints were internal and safe to run without authentication.
- Input & Instruction Weaponization — Instruction Injection / Direct Prompt Injection. Exposed Ollama APIs responded to unauthenticated prompts, allowing arbitrary external users to interact with models.
- Reasoning-Time Execution — Functional Completion Bias / Security Constraint Omission. Exposed chatbot deployments revealed prior LLM conversation history and operational context.
- Tool Invocation — Execution Bypass / Unauthorized Tool Invocation. Some exposed platforms included internet parsing tools, file write functions, code interpretation, and outward integrations.
- Privilege Escalation — Capability Expansion / Tool Scope Escalation. Open agent management interfaces exposed workflows, credentials metadata, and configuration.
- Lateral Movement — Bypassed entirely. Exposed agent workflows and connected credentials create potential paths from the AI layer into business applications.
- Persistence — Bypassed entirely. An attacker can modify stored account or system state so access survives the initial interaction.
- AI Native C2 — Bypassed entirely. Modified workflows or prompts could turn the exposed AI service into a controlled response or redirection channel.
- Action on Objectives — Data Theft / Data Exfiltration via AI. Exposed systems leaked chat history, prompts, workflows, and enabled unauthorized model access.
Why This Isn’t a Traditional Exposure Problem
Traditional exposed services usually expose an admin panel, API, database, or application endpoint. Exposed AI services can expose all of those plus something more dangerous: a reasoning and automation layer.
That reasoning layer may have access to prompts, user history, credentials, tools, files, APIs, workflows, and third-party integrations. In traditional systems, attackers often need to compromise an application first and then discover what it can reach. In exposed AI infrastructure, the system may describe its role, reveal its workflows, and provide a natural language interface to connected capabilities.
This changes the attacker experience. Instead of reverse engineering the application manually, an attacker may be able to ask the AI system what it is, what it can do, what tools it has, and how it is configured.
The security failure is not simply “an endpoint was public.” The failure is that AI deployments are being exposed with the equivalent of unauthenticated access to reasoning, data, tools, and automation.
How to Prevent This Class of Exposure
The required controls are not exotic. They are basic security controls applied rigorously to AI infrastructure.
Discovery and Exposure Control
Organizations must maintain an inventory of all AI applications, model APIs, agent frameworks, chat interfaces, vector databases, workflow tools, and developer-deployed AI services exposed to the internet.
Authentication and Access Control
No AI interface, model endpoint, management console, workflow editor, or tool-connected agent should be reachable without authentication.
Secrets and Credential Hygiene
AI workflows must not expose API keys, plaintext secrets, static credentials, or reusable tokens.
Agent platforms should use scoped, short-lived credentials. Connected tools should follow least privilege. Credential lists should not be visible to unauthenticated users, even if secret values are masked.
Tool and Workflow Hardening
Agents should not have default access to file writes, shell execution, code interpretation, internet parsing, cloud deployment, or sensitive business systems. High-risk tools should require explicit approval.
Sandboxing and Runtime Isolation
Tool execution should happen in isolated sandboxes with network, filesystem, process, and egress restrictions.
Prompt and Conversation Data Protection
Prompts, system messages, workflow definitions, and chat history should be treated as sensitive assets.
Egress Control
AI services should not be allowed to send data to arbitrary external destinations. Outbound network access should be restricted, monitored, and tied to approved use cases.
Stop it Before the Front Door Opens
This incident is a warning that AI exposure is becoming its own class of enterprise attack surface.
The risk is not just that chatbots are public. The risk is that modern AI systems increasingly connect prompts, memory, workflows, tools, credentials, and business logic behind a single natural-language interface. When that interface is exposed, the attacker does not need to break in through the front door. The front door is already open.
The lesson is simple: treat AI infrastructure like production infrastructure, not experimentation infrastructure. Authenticate it, inventory it, isolate it, monitor it, and remove dangerous defaults before attackers find them first.
Lineaje UnifAI closes that gap before it becomes an incident. UnifAI maps your AI inventory, sets policy, and defends at runtime — authenticating every user and agent before access is granted, holding each agent to least-privilege credentials, confining the tools and outbound destinations it can reach, and keeping sensitive data masked at the interface, all enforced outside the exposed surface so an open endpoint can't be turned into a path for exfiltration, tool abuse, or lateral movement.